
Kafka
名字由来
kafka的架构师jay kreps对于kafka的名称由来是这样讲的,由于jay kreps非常喜欢franz kafka,并且觉得kafka这个名字很酷,因此取了个和消息传递系统完全不相干的名称kafka,该名字并没有特别的含义。
kafka的诞生,是为了解决linkedin的数据管道问题,起初linkedin采用了ActiveMQ来进行数据交换,大约是在2010年前后,那时的ActiveMQ还远远无法满足linkedin对数据传递系统的要求,经常由于各种缺陷而导致消息阻塞或者服务无法正常访问,为了能够解决这个问题,linkedin决定研发自己的消息传递系统,当时linkedin的首席架构师jay kreps便开始组织团队进行消息传递系统的研发。
特性
Kafka[1]是一种高吞吐量[2]的分布式发布订阅消息系统,有如下特性:
• 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
• 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
• 支持通过Kafka服务器和消费机集群来分区消息。
• 支持Hadoop并行数据加载。
Kafka通过官网发布了最新版本2.0.0。
术语介绍
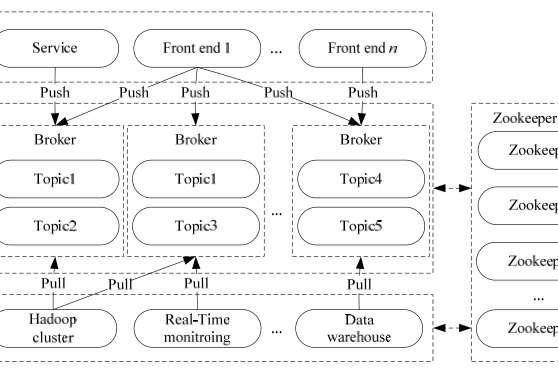
• Broker
• Kafka集群包含一个或多个服务器,这种服务器被称为broker。
• Topic
• 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
• Partition
• Partition是物理上的概念,每个Topic包含一个或多个Partition。
• Producer
• 负责发布消息到Kafka broker。
• Consumer
• 消息消费者,向Kafka broker读取消息的客户端。
• Consumer Group
• 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
参考资料
[1] Apache Kafka官网 · Apache Kafka官网[引用日期2018-01-05]
[2] Benchmarking Apache Kafka: 2 Million Writes Per Se · LinkedIn[引用日期2015-11-20]